Форматированный вывод и логирование отладочной информации
Описание
Почему разработчику нужен цивилизованный вывод отладочной информации
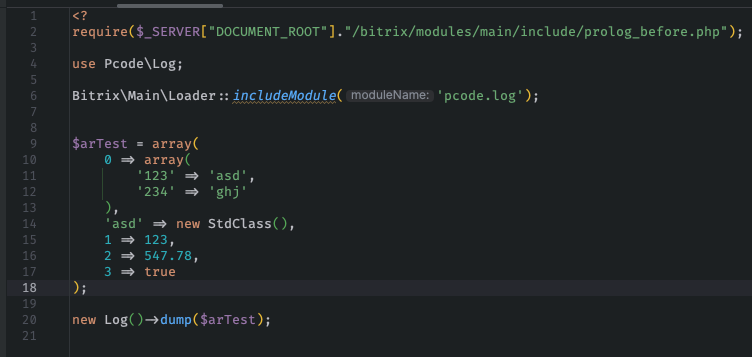
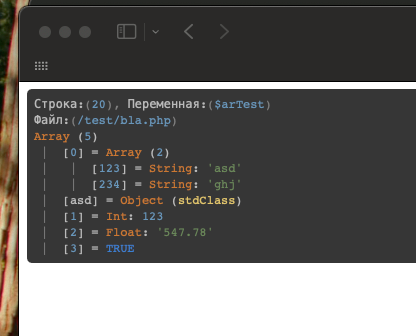
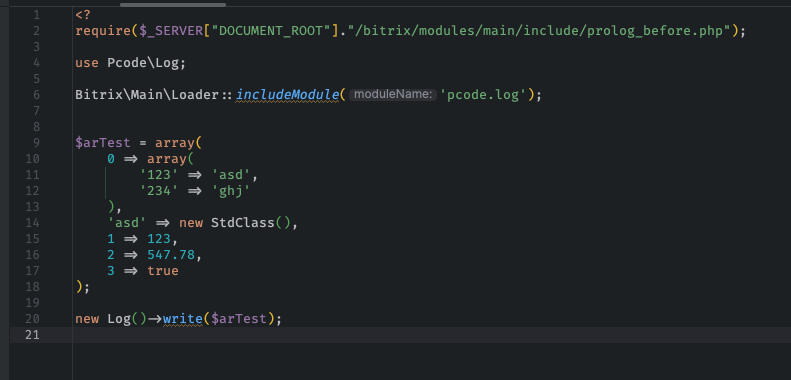
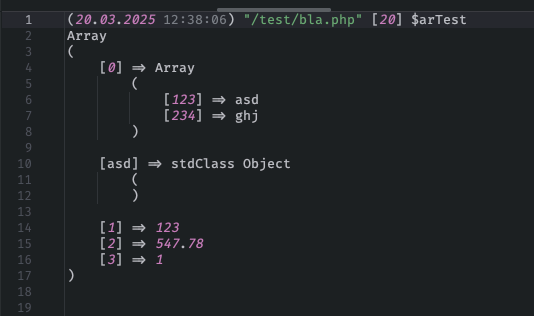
Каждый, кто пишет код на 1С-Битрикс, знает, как выглядит хаос в логах. Сырые дампы массивов, перепутанные сообщения, бесконечные файлы, которые непонятно когда и зачем появились. Стандартный var_dump или print_r хороши только на этапе прототипа, но когда сайт уже работает — такой подход превращается в головную боль. Наше решение для форматированного вывода и логирования меняет правила игры. Вместо того чтобы продираться через неструктурированные данные, вы получаете аккуратно оформленную информацию, которую удобно читать глазами и анализировать. Это не просто «красивости», а реальная экономия часов рабочего времени.
Согласитесь, когда в проекте участвует несколько разработчиков, единый стандарт вывода отладочных данных становится критически важным. Решение обеспечивает именно этот стандарт: любой разработчик, открывший лог, сразу видит понятную структуру, а не мешанину из символов. Вы перестаёте тратить время на расшифровку собственных же дампов — система сама приводит информацию к читаемому виду.
Умное управление лог-файлами: порядок вместо свалки
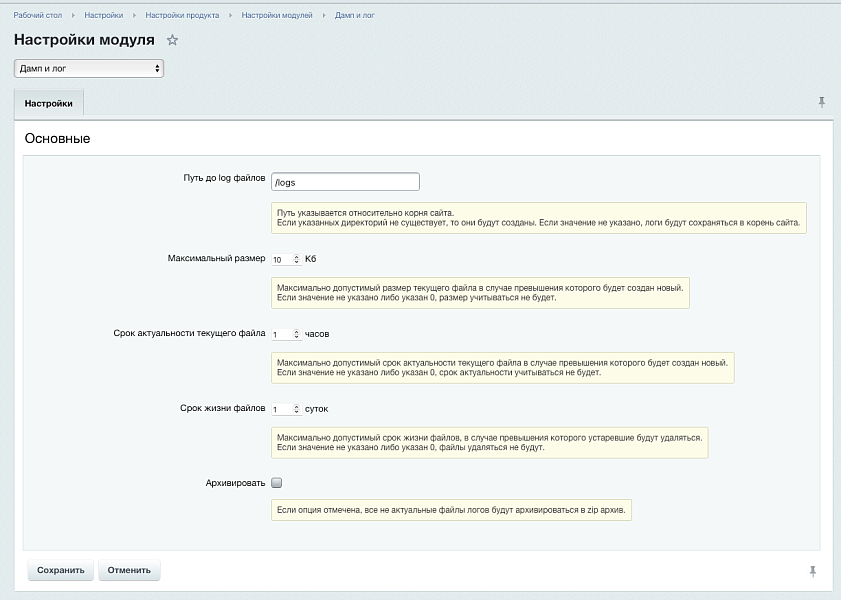
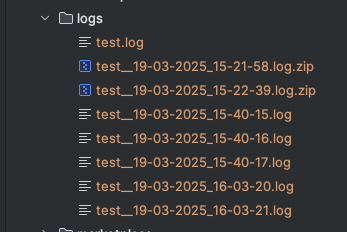
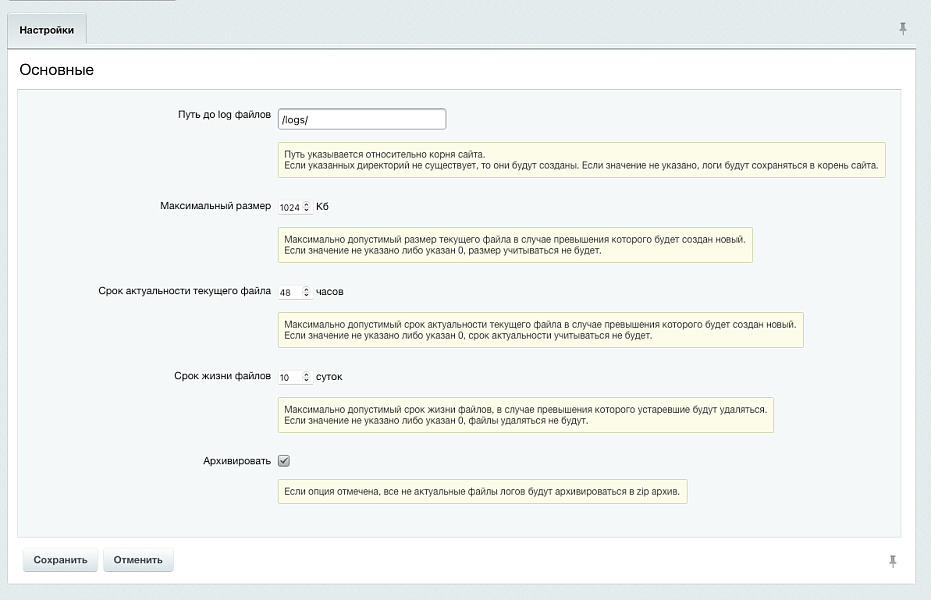
Одна из главных проблем при активной разработке — это бесконтрольный рост логов. Файлы копятся, занимают место на диске, а найти в них что-то нужное становится настоящим квестом. Наше решение решает эту проблему на системном уровне. Вы задаёте два ключевых параметра: максимальный размер лог-файла и срок его актуальности. Всё, что выходит за эти рамки, автоматически обрабатывается — старые данные не удаляются безвозвратно, а архивируются. Это значит, что вы всегда можете вернуться к истории, если это необходимо, но при этом сервер не захламляется тоннами мусора.
Представьте, что вы ищете ошибку, которая произошла две недели назад. При обычном подходе лог за это время уже мог быть перезаписан или удалён вручную. Здесь же система сохраняет архивные копии, и вы спокойно открываете нужный период. При этом настройки гибкие: вы можете указать, что логи старше 30 дней автоматически уходят в архив, а если архив превышает определённый объём — самые старые записи удаляются. Получается самоподдерживающаяся система, которая не требует постоянного ручного контроля.
Гибкость на уровне кода: индивидуальные настройки для каждой задачи
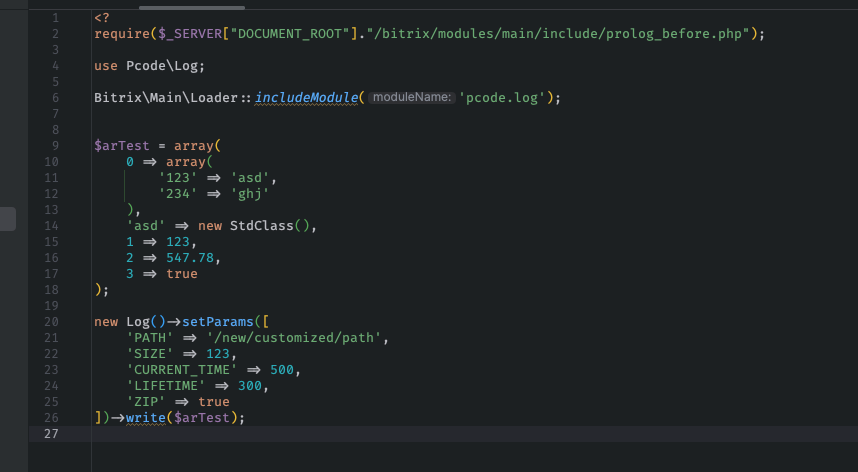
Глобальные настройки — это хорошо, но в реальной разработке часто возникают ситуации, когда нужно отступить от общих правил. Например, вы отлаживаете критичный компонент и хотите писать логи с максимальной детализацией, не дожидаясь, пока они дойдут до общего файла. Или, наоборот, для тестового скрипта нужно временно отключить логирование вообще. Наше решение позволяет переопределить глобальные параметры прямо в коде для каждого конкретного случая. Вы просто передаёте индивидуальные настройки в момент вызова функции логирования, и система применяет их только для этого блока.
Это особенно удобно, когда на одном проекте работают разные модули с разными требованиями. Для платёжного шлюза вы можете установить один уровень детализации и срок хранения, а для корзины — совершенно другой. И всё это не конфликтует между собой, не требует правки общих конфигов и не ломает логику других разработчиков. Гибкость на уровне кода — это именно то, чего не хватает стандартным инструментам отладки в Битриксе.
Как это ускоряет разработку и снижает количество багов
Форматированный вывод и организованное логирование — это не просто удобные фичи, а инструменты, которые напрямую влияют на скорость и качество работы. Когда вы видите чёткую структуру данных, вы быстрее находите несоответствия и ошибки. Когда логи не теряются и не захламляют сервер, вы можете анализировать поведение системы на длинных дистанциях. Это особенно важно для сложных проектов, где ошибка может проявиться только через несколько дней или при определённой комбинации условий.
Кроме того, архивация старых логов и автоматическая очистка устаревших данных снижают нагрузку на сервер и минимизируют риск того, что диск заполнится в самый неподходящий момент. Разработчику не нужно помнить о том, чтобы вручную почистить папку с логами — всё работает по заданным правилам. В результате вы тратите меньше времени на администрирование и больше — на написание кода и исправление реальных ошибок. Решение становится незаметным, но незаменимым помощником в ежедневной работе.
Практические сценарии использования в повседневной разработке
Представьте, что вы работаете над кастомным компонентом каталога. Вместо того чтобы вставлять var_dump в десяток мест и потом искать вывод в разных частях страницы, вы используете единую функцию форматированного вывода. Вся информация собирается в одном месте, структурируется по времени и контексту. Если что-то пошло не так — вы открываете лог и видите полную картину: какие данные пришли, какие преобразования прошли, на каком шаге произошёл сбой. Это сокращает время поиска ошибки с часов до минут.
Другой сценарий — работа с внешними API. Часто нужно логировать запросы и ответы, чтобы отследить, что именно передаётся на внешний сервер и что приходит обратно. С нашим решением вы можете настроить отдельный лог для каждого внешнего сервиса, с собственным размером и сроком хранения. А если интеграция тестовая — просто отключить логирование, не трогая код. Всё это делает процесс разработки предсказуемым и контролируемым, а значит — более надёжным.
Часто задаваемые вопросы
Характеристики
| Версия | 1.0.1 |
| Добавлен | 07.04.2025 |
| Обновлён | 09.04.2025 |
| Установок | Менее 50 раз |
| Код | pcode.log |
| Адаптивный | Нет |
| Composite | Нет |